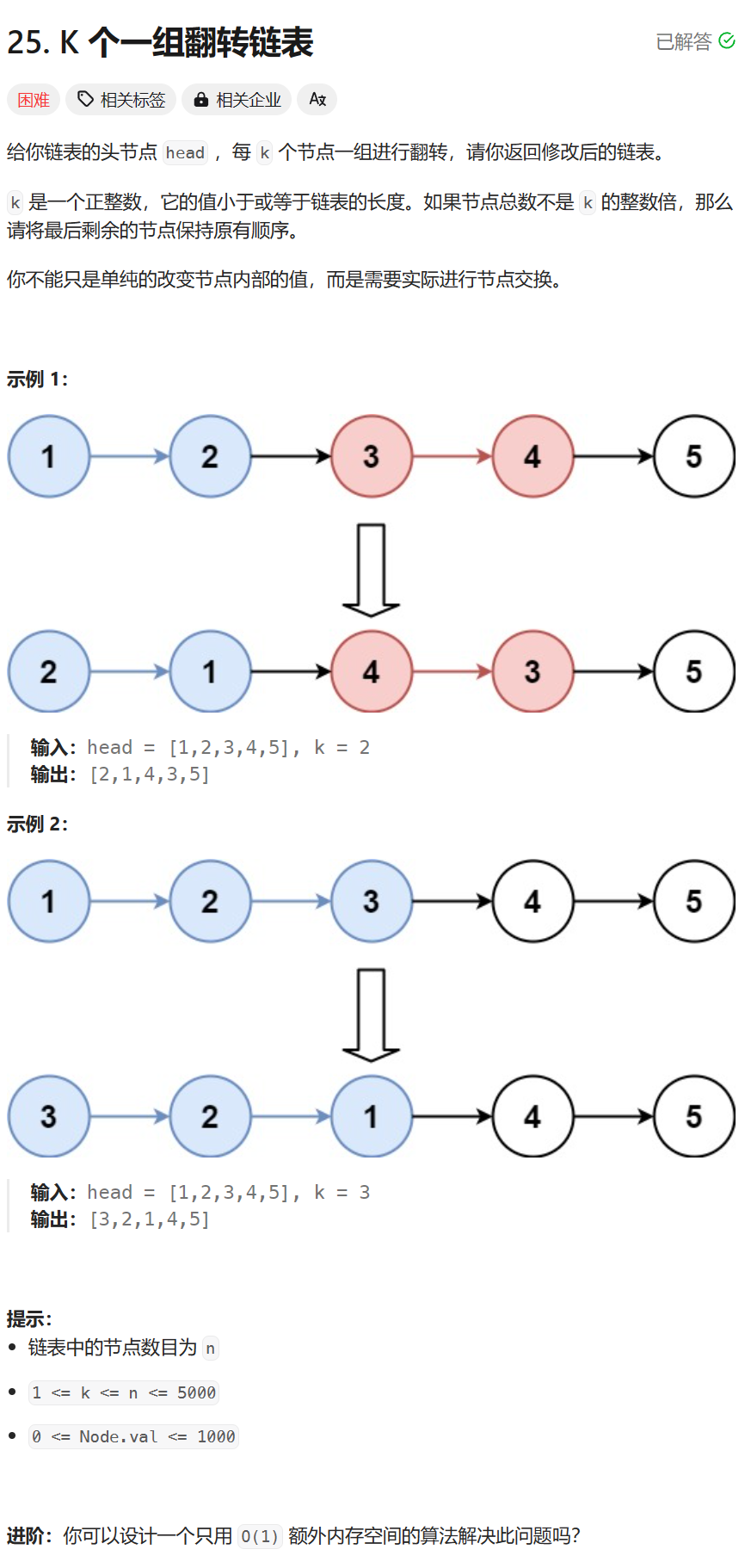
在大多数时间序列预测中,尽管有Prophet和NeuralProphet等方便的工具,但是了解基于树的模型仍然具有很高的价值。尤其是在监督学习模型中,仅仅使用单变量时间序列似乎信息有限,预测也比较困难。因此,为了生成足够的特征,需要采取一些方法,例如创建大量的滞后变量。此外,关于预测目标值,也要用过去的项来预测未来的项,而且需要决定是一步领先还是多步领先。
从单变量时间序列中创建特征
在单变量时间序列中一般只能获得有限的信息。ARIMA 模型使用过去的值来预测未来的值,因此过去的值是重要的候选特征,可以创建许多滞后回归因子。时间指数是一个有价值的领域,因此可以基于此创建特征。由于日历上的事件和年度事件在生活中不断重复,它们为过去留下了印记,为未来提供了教益。因此可以从与时间相关的特征入手。
创建基于时间的特征
创建基于时间的特征,包括日期、星期、季度等各种特征,通过 pandas series 的 "date" 类中提供的一系列函数,可以轻松实现这些需求。
def create_date_features(df):
df['month'] = df.date.dt.month
df['day_of_month'] = df.date.dt.day
df['day_of_year'] = df.date.dt.dayofyear
df['week_of_year'] = df.date.dt.weekofyear
df['day_of_week'] = df.date.dt.dayofweek + 1
df['year'] = df.date.dt.year
df['quarter'] = df.date.dt.quarter
df['hour_of_day'] = df.date.dt.hour
df['weekday'] = df.date.dt.weekday
df['is_year_start'] = df.date.dt.is_year_start.astype(int)
df['is_year_end'] = df.date.dt.is_year_end.astype(int)
df['is_month_start'] = df.date.dt.is_month_start.astype(int)
df['is_month_end'] = df.date.dt.is_month_end.astype(int)
df['is_quarter_start'] = df.date.dt.is_quarter_start.astype(int)
df['is_quarter_end'] = df.date.dt.is_quarter_end.astype(int)
df['is_quarter_end'] = df.date.dt.is_quarter_end.astype(int)
return df这里我使用的数据集为本地的数据集,需要可自行搜集下载,除date、open字段外,它还包含其他字段(不做说明):
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
from pymysql import connect
from sqlalchemy import create_engine, text
def check_info(code):
engine = create_engine('mysql+pymysql://root:152617@127.0.0.1:3306/stock_info')
conn = engine.connect()
result = conn.execute(text("SELECT * FROM stocks WHERE stock_code = " + code))
conn.close()
return result将使用 date(日期 )和open(开盘价)字段来处理单变量时间序列。
df = pd.DataFrame(check_info('000001'))[['date','open']]
df["date"] = pd.to_datetime(df["date"])
df = df.sort_values(by='date')
df.head()
这里数据量不多,因为有很久没有运行脚本去自动更新数据库了,大概只有:

进行可视化:
plt.figure(figsize=(10,4))
plt.plot(df['date'], df["open"])
plt.xlabel("date")
plt.ylabel("open_price")
plt.show()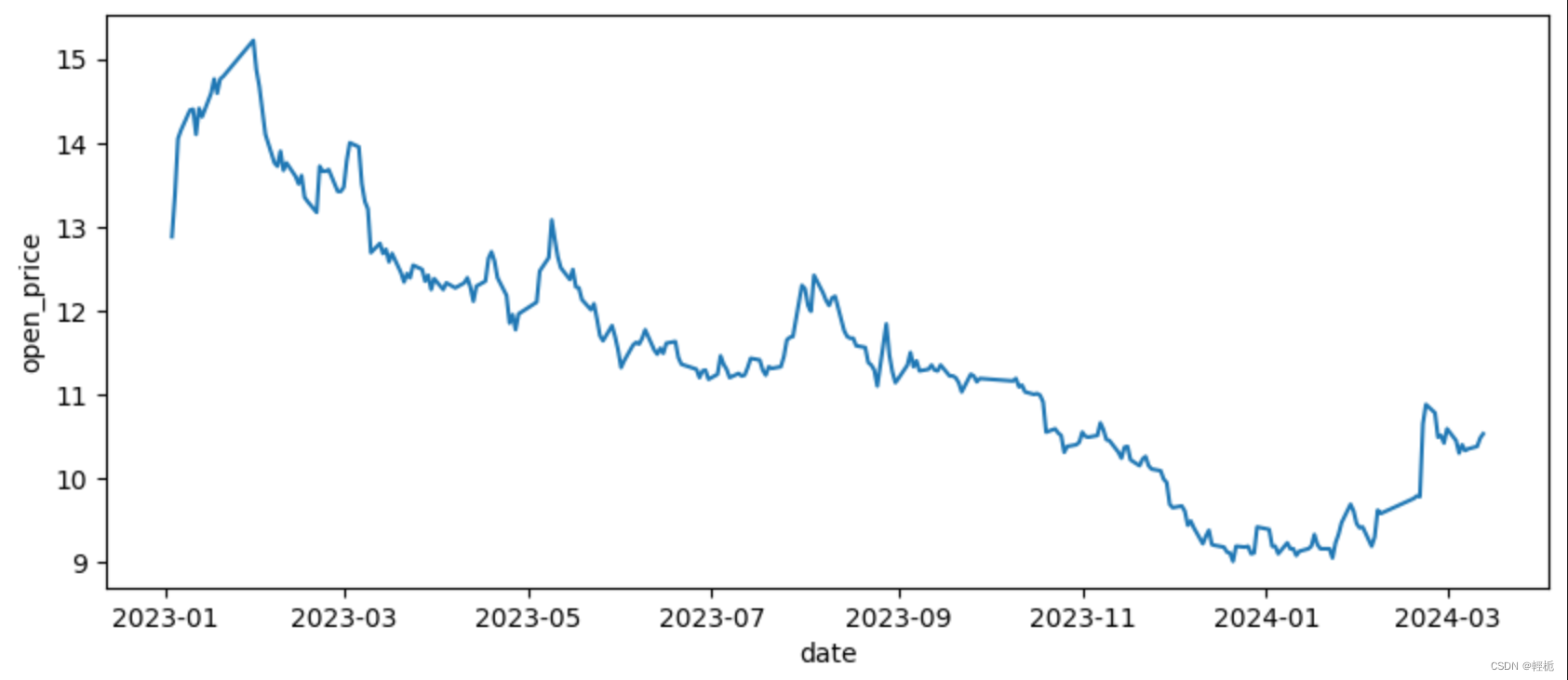 显而易见的下跌趋势。
显而易见的下跌趋势。
应用函数来创建日期特征:
df = create_date_features(df)
df.head()
note:这里需要进行一个步骤。在上面模型中,有几个字段不应作为数字特征,而应作为分类特征。需要把它们转化为虚拟变量
to_dummy = ['weekday', 'month', 'quarter', 'year', 'day_of_month', 'week_of_year', 'day_of_week', 'hour_of_day']
df = pd.get_dummies(df, columns= to_dummy)一个特征列表就创建好了。
创建滞后特征和未来特征
在自动回归模型中,回归变量是滞后值。可以使用 .shift(n) 来创建滞后特征。接下来,在数据集 ff 中创建三个滞后特征。
ff = df.copy()
ff['open-1'] = ff['open'].shift(1)
ff['openy-2'] = ff['open'].shift(2)
ff['open-3'] = ff['open'].shift(3)
ff.head()
编写一个 forloop 来创建多个滞后特征。下面将在不同的数据集 ff 中创建 5 个滞后变量:
ff = df.copy()
def create_lagged(df, n_vars):
# Use a forloop
for i in range(n_vars):
# The name will be y-1, y-2, etc.
name = ('open-%d' % (i+1))
df[name] = df['open'].shift(i+1)
return df
ff = create_lagged(ff, 5)
ff.head()
显然,也可以将数值前移,使其成为未来的目标值,如下所示:
ff = df.copy()
ff['open+1'] = ff['open'].shift(-1)
ff['open+2'] = ff['open'].shift(-2)
ff['open+3'] = ff['open'].shift(-3)
ff.tail()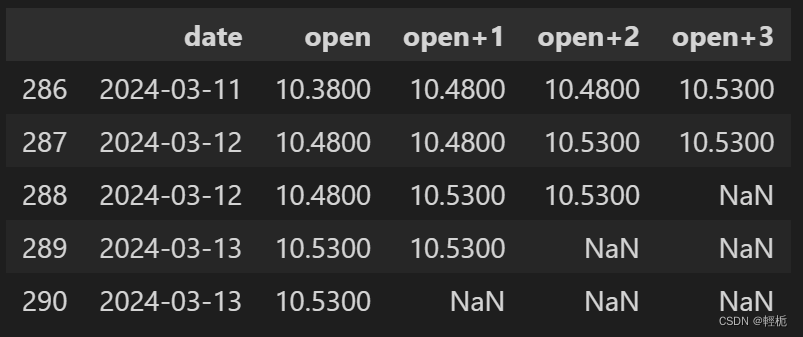
正式为建模数据 df 创建 25 个滞后变量:
df = create_lagged(df, 25)
df.columns数据集中包含了['date', 'open', 'open-1', ..., 'open-25']的数据。在此基础上,可以进行一系列汇总统计,如过去 n 小时、n 天或 n 周的总和或平均值。
创建移动平均值
另外,可以创建1,3,5,7,10的移动平均值。
def roll_mean_features(df, windows):
df = df.copy()
for window in windows:
df['mv_' + str(window)] = df['open'].transform(
lambda x: x.shift(1).rolling(window=window, min_periods=1, win_type="triang").mean())
# min_periods=1表示即使在窗口初期数据不足时也计算平均值
# win_type='triang'指定了窗口的权重类型为三角形(Triangular)权重
return df
df = roll_mean_features(df, [1, 3, 5, 7, 10])
df.tail()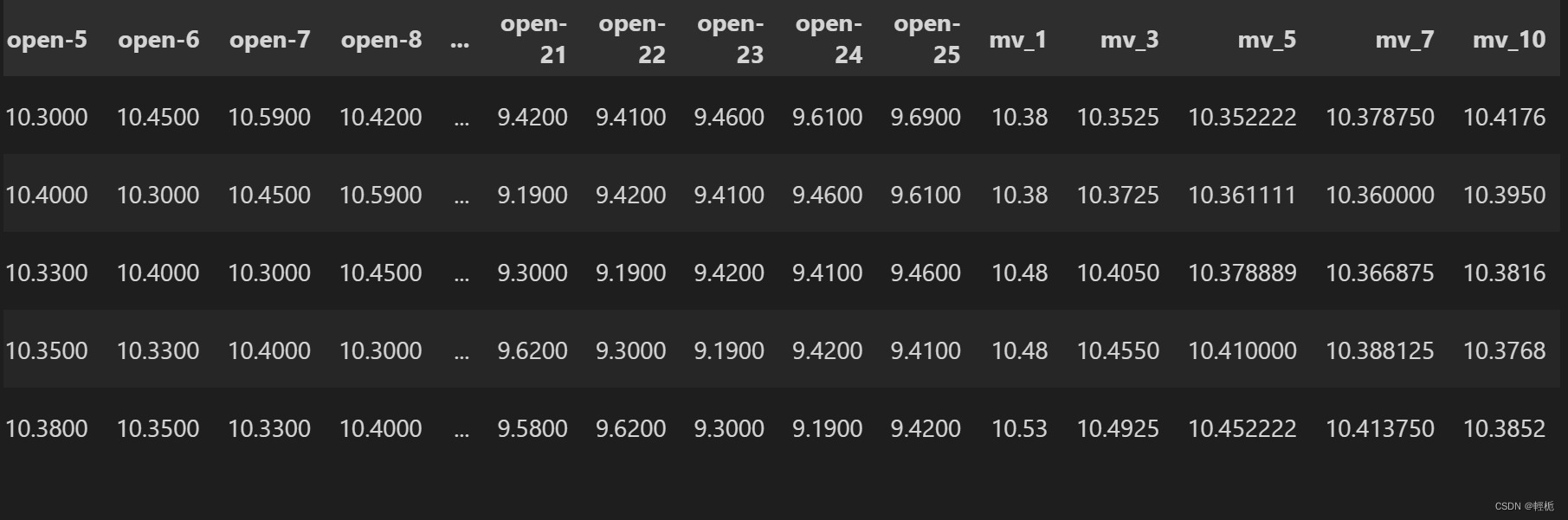
监督学习框架用于提前预测。模型目标是 open,特征包括滞后项 open-1到open-25以及时间相关和移动平均变量。

该模型可以通过yt-1到yt-25产生下一期的yt,即提前一步预测。在现实应用中,多步预测也很常见,传统方法是建立n个模型来预测接下来的n期。

建立 LightGBM 预测模型
LightGBM是微软开发的梯度提升框架,它使用叶向树生长以提高准确性。相比之下,level-wise树会尝试在同一级别的分支上生长,看起来更平衡。由于其能够处理大型数据集和并行化训练,因此比其他提升算法更高效、更快速,同时内存占用更低。此外,它原生支持分类特征,无需进行单次编码。梯度提升模型是机器学习算法的一种,它将多个较弱的模型组合在一起,从而创建一个强大的预测模型。它的基本思想是迭代训练决策树,每棵树都试图纠正前一棵树所犯的错误。最终的预测结果是所有决策树预测结果的总和。梯度提升模型特别适用于处理复杂的数据集,可以处理大量特征和特征之间的交互,并且对过度拟合也很稳健,同时能够处理缺失值。常用的算法有梯度提升机(GBM)、XGB 和 LightGBM。
划分训练和测试集
将时间序列切割成 "实时" 数据作为训练数据,"非实时" 数据作为测试数据:
from datetime import timedelta
# Count the days
num_days = (df['date'].max() - df['date'].min()).days
# reserve 20% for out-of-time
oot = num_days * 0.2
# Get the cutdate
cutdate = df['date'].max() - timedelta(days = oot)
# Create the training data
train = df.loc[(df['date'] <= cutdate), :]
print("Training data: from", train['date'].min(), "to", train['date'].max())
# Create the test data
test = df.loc[(df['date'] > cutdate), :]
print("Test data: from", test['date'].min(), "to", test['date'].max())
LightGBM 建模
LightGBM 有许多超参数可以调整。可指定关键超参数:
import lightgbm as lgb
lgb_params = {# 平均绝对误差
'metric': {'mae'},
# 树中树叶的数量
'num_leaves': 6, # 10以上训练效果才比较好
# 学习日期
'learning_rate': 0.02,
# 随机选取 80% 的特征到训练
'feature_fraction': 0.8,
# 树的最大深度
'max_depth':5,
# 忽略训练进度(不显示任何内容)
'verbose': 0,
# 提升迭代次数
'num_boost_round': 150,
# 如果精度没有提高,就停止训练
'early_stopping_rounds': 200,
# 使用计算机上的所有内核
'nthread': -1}LightGBM 有一个".Dataset()"代码类,用于打包目标变量、回归变量和数据。如下所示,操作非常简单。
train = train.dropna()
Y_train = train[['open']]
X_train = train[cols]
Y_test = test[['open']]
X_test = test[cols]
from sklearn import preprocessing
lbl = preprocessing.LabelEncoder()
Y_train['open'] = lbl.fit_transform(Y_train['open'].astype(float))
Y_test['open'] = lbl.fit_transform(Y_test['open'].astype(float))
for c in cols:
X_train[c] = lbl.fit_transform(X_train[c].astype(float)) #将提示的包含错误数据类型这一列进行转换
X_test[c] = lbl.fit_transform(X_test[c].astype(float))
# Use the Dataset class of lightGBM
lgbtrain = lgb.Dataset(data=X_train, label=Y_train, feature_name=cols)
lgbtest = lgb.Dataset(data=X_test, label=Y_test, reference=lgbtrain, feature_name=cols)
model = lgb.train(lgb_params, lgbtrain,
valid_sets=[lgbtrain, lgbtest],
num_boost_round=1000
)在这里需要注意你的数据特征或者label里面有没有NA,否则会出现报错:pandas dtype only support int float bool,检查数据是否是object
其次如果出现warm:-inf意味着可能你的数据过于稀疏(数据中特征的分布非常不均匀,或者特征值的范围很小,可能导致分割增益为负);特征质量差(某些特征可能对模型预测没有帮助,或者特征与目标变量的关联性太弱);参数设置(min_data_in_leaf(叶子节点最小样本数)或min_gain_to_split(最小增益阈值)设置得过高,导致模型在寻找分割时过于保守);需要进行参数重新设定
预测准确性评估
完成后,就可以得出训练数据和测试数据的预测值,并评估预测准确度。使用标准指标平均绝对百分比误差 (MAPE) 来评估预测准确度。MAPE 是绝对百分比误差的平均值,10% 的 MAPE 意味着预测值和实际值之间的平均偏差为 10%。
from sklearn.metrics import mean_absolute_percentage_error
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
mean_absolute_percentage_error(Y_test, y_pred_test)此处数据量过少,提取的特征很勉强,训练效果不好,就不放了。
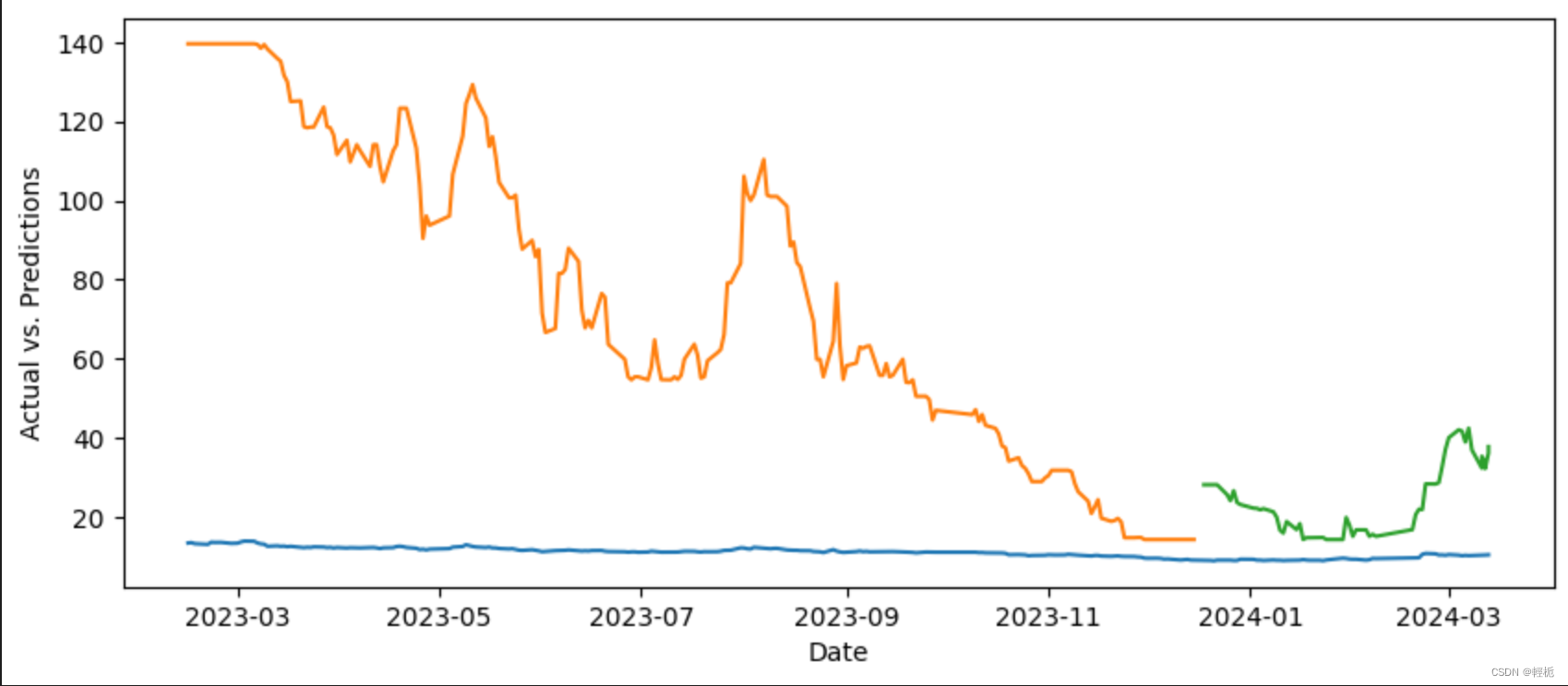
实际值与预测值可视化
# 将预测值添加到训练期
train_pred = train.copy()
train_pred['open_pred_train'] = y_pred_train
# 将预测值添加到测试期
test_pred = test.copy()
test_pred['open_pred_test'] = y_pred_test
print([train_pred.shape, test_pred.shape])
# 合并训练期和测试期
actual_pred = pd.concat([train_pred, test_pred], axis=0)
actual_pred.shape
# 用蓝色绘制实际值
# 用橙色绘制训练期的预测值
# 用绿色标出测试期的预测值
plt.figure(figsize=(10,4))
plt.plot(actual_pred['date'], actual_pred[["open",'open_pred_train','open_pred_test']])
plt.xlabel("Date")
plt.ylabel("Actual vs. Predictions")
plt.show()不忍直视
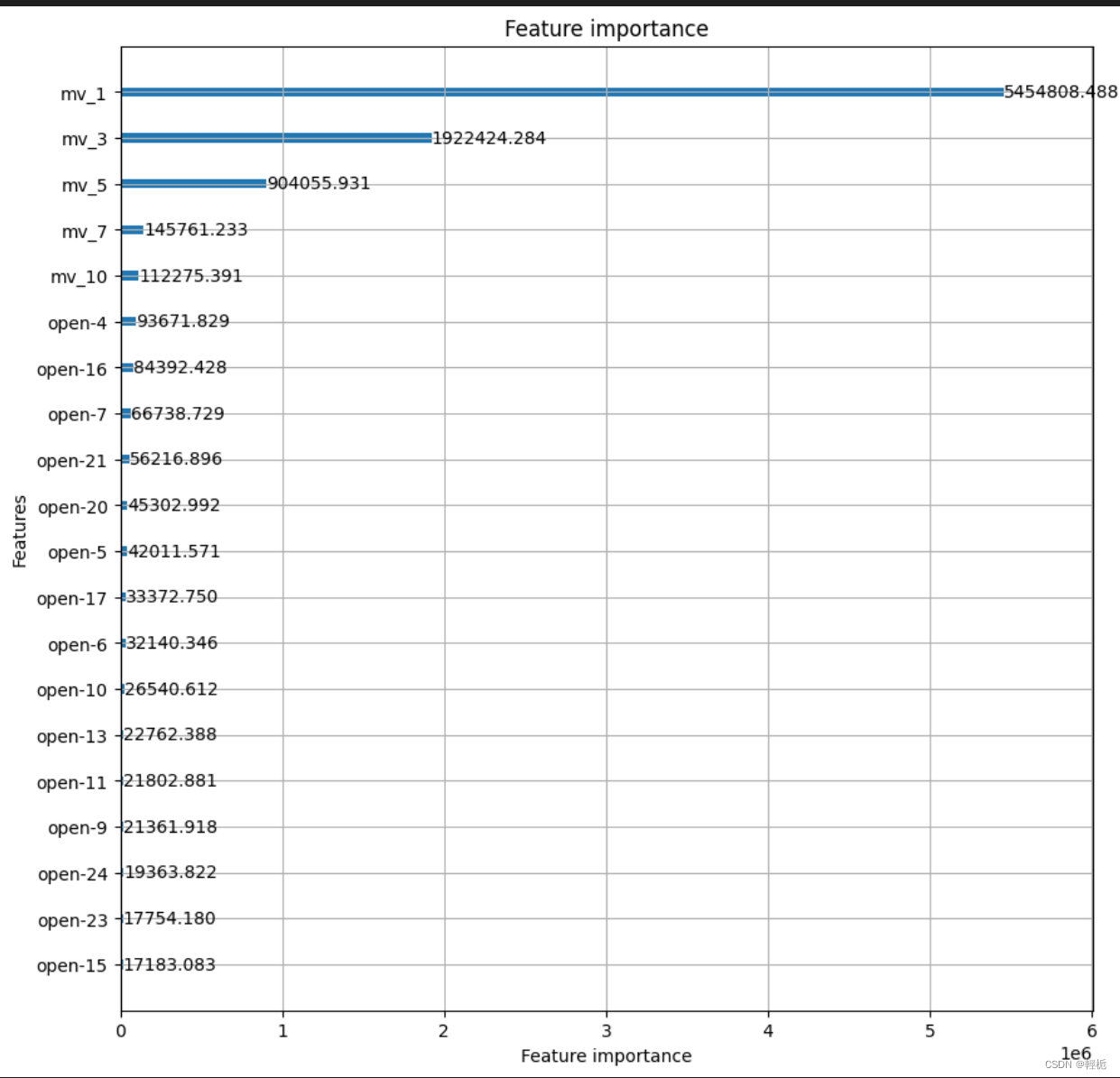
模型可解释性
基于树的模型的优势之一是其可视性。可以通过变量重要性图直观地看到特征对预测的影响。
lgb.plot_importance(model,
max_num_features=20,
figsize=(10, 10),
importance_type="gain")
plt.show()特征重要性图显示,影响最大的三个变量是 *、*和*。 毫无解释力。变更数据重新检验即可。
这里探讨了单变量时间序列特征的创建方法,以及如何将其纳入基于树的监督学习框架中。利用 lightGBM 模型进行了一步预测,并展示了如何利用变量显著图提高模型可解释性。
对于timeseries predict进一步还有用LSTM进行分析。


![[方法] Unity 实现仿《原神》第三人称跟随相机 v1.1](https://img-blog.csdnimg.cn/direct/26d149d2c5bf47a081a5fa7cc458b7b4.png)